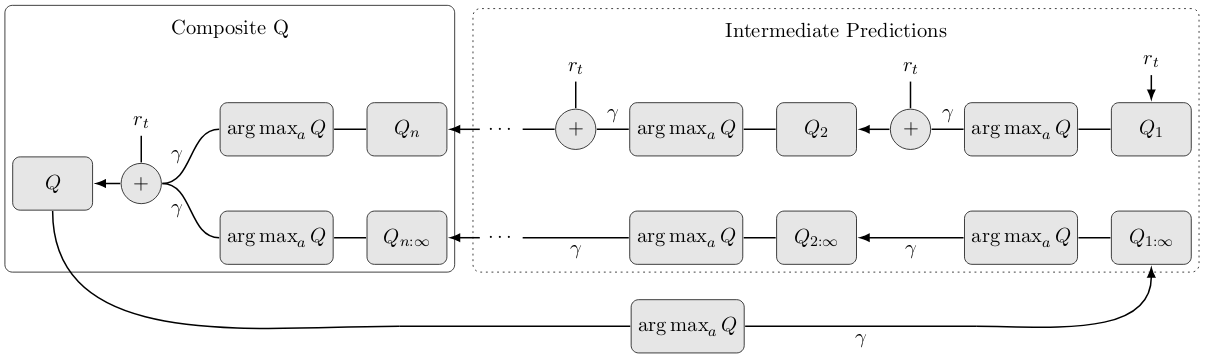
Gabriel Kalweit*, Maria Huegle*, Moritz Werling and Joschka Boedecker
NeurIPS 2020: Deep Inverse Q-Learning with Constraints
Paper (arxiv) CiteIntroduction
Popular Maximum Entropy Inverse Reinforcement Learning approaches require the computation of expected state visitation frequencies for the optimal policy under an estimate of the reward function. This usually requires intermediate value estimation in the inner loop of the algorithm, slowing down convergence considerably. In this work, we introduce a novel class of algorithms that only needs to solve the MDP underlying the demonstrated behavior once to recover the expert policy. This is possible through a formulation that exploits a probabilistic behavior assumption for the demonstrations within the structure of Q-learning. We propose Inverse Action-value Iteration which is able to fully recover an underlying reward of an external agent in closed-form analytically. We further provide an accompanying class of sampling-based variants which do not depend on a model of the environment. We show how to extend this class of algorithms to continuous state-spaces via function approximation and how to estimate a corresponding action-value function, leading to a policy as close as possible to the policy of the external agent, while optionally satisfying a list of predefined hard constraints. We evaluate the resulting algorithms called Inverse Action-value Iteration, Inverse Q-learning and Deep Inverse Q-learning on the Objectworld benchmark, showing a speedup of up to several orders of magnitude compared to (Deep) Max-Entropy algorithms. We further apply Deep Constrained Inverse Q-learning on the task of learning autonomous lane-changes in the open-source simulator SUMO achieving competent driving after training on data corresponding to 30 minutes of demonstrations. The scheme of Deep Constrained Inverse Q-learning can be seen in Fig. 1.

Fig. 1: Scheme of Deep Constrained Inverse Q-learning for the constrained transfer of unconstrained driving demonstrations, leading to optimal constrained imitation.
Technical Approach
Inverse Action-value Iteration
We start with the derivation of model-based Inverse Action-value Iteration (IAVI), where we first establish a relationship between Q-values of a state action-pair $(s,a)$ and the Q-values of all other actions in this state. We assume that the trajectories are collected by an agent following a stochastic policy with an underlying Boltzmann distribution according to its unknown optimal value function. For a given optimal action-value function $Q^*$, the corresponding distribution is: $$ \pi^\mathcal{E}(a|s) := \frac{\exp(Q^*(s, a))}{\sum_{A\in\mathcal{A}}\exp(Q^*(s, A))},$$ for all actions $a\in\mathcal{A}$. Rearranging gives: $$ \sum_{A\in\mathcal{A}}\exp(Q^*(s, A)) = \frac{\exp(Q^*(s, a))}{\pi^\mathcal{E}(a|s)} \text{ and } \exp(Q^*(s, a)) = \pi^\mathcal{E}(a|s)\sum_{A\in\mathcal{A}}\exp(Q^*(s, A)).$$ Denoting the set of actions excluding action $a$ as $\mathcal{A}_{\bar a}$, we can express the Q-values for an action $a$ in terms of Q-values for any action $b\in\mathcal{A}_{\bar a}$ in state $s$ and the probabilities for taking these actions: $$ \exp(Q^*(s, a)) =\pi^\mathcal{E}(a|s)\sum_{A\in\mathcal{A}}\exp(Q^*(s, A)) = \frac{\pi^\mathcal{E}(a|s)}{\pi^\mathcal{E}(b|s)}\exp(Q^*(s, b)).$$ Taking the log then leads to $$ Q^*(s, a)=Q^*(s, b) + \log(\pi^\mathcal{E}(a|s)) - \log(\pi^\mathcal{E}(b|s)).$$ Thus, we can relate the optimal value of action $a$ with the optimal values of all other actions in the same state by including the respective log-probabilities: $$(n-1) Q^*(s, a) = (n-1) \log(\pi^\mathcal{E}(a|s)) + \sum_{b\in\mathcal{A}_{\bar a}} Q^*(s,b) - \log(\pi^\mathcal{E}(b|s)).$$ The optimal action-values for state $s$ and action $a$ are composed of immediate reward $r(s, a)$ and the optimal action-value for the next state as given by the transition model, i.e. $Q^*(s, a)=r(s, a) + \gamma \max_{a'} \mathbf{E}_{s'\sim\mathcal{M}(s,a,s')}[Q^*(s', a')]$. Using this definition to replace the Q-values and defining the difference between the log-probability and the discounted value of the next state as: $$\eta_s^a =: \log(\pi^\mathcal{E}(a|s)) - \gamma \max_{a'}\mathbf{E}_{s'\sim\mathcal{M}(s,a,s')}[Q^*(s', a')],$$ we can then solve for the immediate reward: $$r(s, a) = \eta_s^a + \frac{1}{n-1} \sum_{b\in\mathcal{A}_{\bar a}} r(s, b) - \eta_s^b.$$ Formulating this equation for all actions $a_i \in \mathcal{A}$ results in a system of linear equations $\mathcal{X}_\mathcal{A}(s)\mathcal{R}_\mathcal{A}(s) = \mathcal{Y}_\mathcal{A}(s)$, with reward vector $\mathcal{R}_\mathcal{A}(s)$, coefficient matrix $\mathcal{X}_\mathcal{A}(s)$ and target vector $\mathcal{Y}_\mathcal{A}(s)$: $$ \begin{bmatrix} 1 & -\frac{1}{n-1} & \dots & -\frac{1}{n-1} \\ -\frac{1}{n-1} & 1 & \dots& -\frac{1}{n-1}\\ \vdots&\vdots & \ddots & \vdots\\ -\frac{1}{n-1} & -\frac{1}{n-1} & \dots & 1 \\ \end{bmatrix} \begin{bmatrix} r(s,a_1)\\ r(s,a_2)\\ \vdots\\ r(s,a_n)\\ \end{bmatrix} = \begin{bmatrix} \eta_s^{a_1} -\frac{1}{n-1}\sum_{b\in\mathcal{A}_{\overline{a_1}}} \eta_b^s\\ \eta_s^{a_2} -\frac{1}{n-1}\sum_{b\in\mathcal{A}_{\overline{a_2}}} \eta_b^s\\ \vdots\\ \eta_s^{a_n} -\frac{1}{n-1}\sum_{b\in\mathcal{A}_{\overline{a_n}}} \eta_b^s\\ \end{bmatrix}.$$
Tabular Inverse Q-learning
To relax the assumption of an existing transition model and action probabilities, we extend the Inverse Action-value Iteration to a sampling-based algorithm. For every transition $(s, a, s')$, we update the reward function using stochastic approximation: $$ r(s, a) \leftarrow (1 - \alpha_r) r(s,a)+ \alpha_r \left( \eta_s^a + \frac{1}{n-1} \sum_{b\in\mathcal{A}_{\bar a}} r(s, b) - \eta_s^b \right),$$ with learning rate $\alpha_r$. Additionally, we need a state-action visitation counter $\rho(s, a)$ for state-action pairs to calculate their respective log-probabilities: $\tilde{\pi}^\mathcal{E}(a|s) =: \rho(s, a) / \sum_{A \in \mathcal{A}} \rho(s, A).$ Therefore, we approximate $\eta_s^a$ by $\tilde{\eta}_s^a =: \log(\tilde{\pi}^\mathcal{E}(a|s)) - \gamma\max_{a'}\mathbf{E}_{s'\sim\mathcal{M}(s,a,s')}[Q^*(s', a')]. $ In order to avoid the need of a model $\mathcal{M}$, we evaluate all other actions via Shifted Q-functions as in Kalweit et al.: $$Q^\text{Sh}(s,a) =: \gamma\max_{a'}\mathbf{E}_{s'\sim\mathcal{M}(s,a,s')}[Q^*(s', a')],$$ i.e. $Q^\text{Sh}(s,a)$ skips the immediate reward for taking $a$ in $s$ and only considers the discounted Q-value of the next state $s'$ for the maximizing action $a'$. We then formalize $\tilde{\eta}_s^a$ as: $$\tilde{\eta}_s^a =:\log(\tilde{\pi}^\mathcal{E}(a|s)) - \gamma \max_{a'} \mathbf{E}_{s'\sim\mathcal{M}(s,a,s')}[Q^*(s', a')]= \log(\tilde{\pi}^\mathcal{E}(a|s)) - Q^{\text{Sh}}(s, a).$$ Combining this with the count-based approximation $\tilde{\pi}^\mathcal{E}(a|s)$ and updating $Q^\text{Sh}$, $r$, and $Q$ via stochastic approximation yields the model-free Tabular Inverse Q-learning algorithm (IQL).
Deep Inverse Q-learning
To cope with continuous state-spaces, we now introduce a variant of IQL with function approximation. We estimate reward function $r$ with function approximator $r(\cdot, \cdot|\theta^r)$, parameterized by $\theta^r$. The same holds for $Q$ and $Q^\text{Sh}$, represented by $Q(\cdot, \cdot|\theta^Q)$ and $Q^\text{Sh}(\cdot, \cdot|\theta^{\text{Sh}})$ with parameters $\theta^Q$ and $\theta^{\text{Sh}}$. To alleviate the problem of moving targets, we further introduce target networks for $r(\cdot, \cdot|\theta^r)$, $Q(\cdot, \cdot|\theta^Q)$ and $Q ^\text{Sh}(\cdot, \cdot|\theta^{\text{Sh}})$, denoted by $r'(\cdot, \cdot|\theta^{r\prime})$, $Q'(\cdot, \cdot|\theta^{Q\prime})$ and $Q ^{\text{Sh}\prime}(\cdot, \cdot|\theta^{{\text{Sh}\prime}})$ and parameterized by $\theta^{r\prime}$, $\theta^{Q\prime}$ and $\theta^{{\text{Sh}\prime}}$, respectively. Each collected transition $(s_t, a_t, s_{t+1})$, either online or in a fixed batch, is stored in replay buffer $\mathcal{D}$. We then sample minibatches $(s_i, a_i, s_{i+1})_{1\leq i \leq m}$ from $\mathcal{D}$ to update the parameters of our function approximators. First, we calculate the target for the Shifted Q-function: $$y^\text{Sh}_i =:\gamma\max_a Q'(s_{i+1},a|\theta^{Q\prime}),$$ and then apply one step of gradient descent on the mean squared error to the respective predictions, i.e. $\mathcal{L}(\theta^\text{Sh})=\frac{1}{m}\sum_i (Q^\text{Sh}(s_i, a_i|\theta^{\text{Sh}}) - y^\text{Sh}_i)^2$. We approximate the state-action visitation by classifier $\rho(\cdot, \cdot|\theta ^\rho)$, parameterized by $\theta^\rho$ and with linear output. Applying the softmax on the outputs of $\rho(\cdot, \cdot|\theta ^\rho)$ then maps each state $s$ to a probability distribution over actions $a_j|_{1\leq j\leq n}$. Classifier $\rho(\cdot, \cdot|\theta^\rho)$ is trained to minimize the cross entropy between its induced probability distribution and the corresponding targets, i.e.: $\mathcal{L}(\theta^\rho)=\frac{1}{m}\sum_i -\rho(s_i, a_i)+\log \sum_{j\neq i}\exp{\rho(s_i, a_j)}.$ Given the predictions of $\rho(\cdot, \cdot|\theta^\rho)$, we can calculate targets $y^r_i$ for reward estimation $r(\cdot, \cdot|\theta^r)$ by: $$y^r_i =:\tilde{\eta}_{s_i}^{a_i}+\frac{1}{n-1}\sum\limits_{b\in\mathcal{A}_{\overline{a_i}}}r'(s_i, b|\theta^{r\prime}) - \tilde{\eta}^b_{s_i},$$ and apply gradient descent on the mean squared error $\mathcal{L}(\theta^r)=\frac{1}{m}\sum_i (r(s_i, a_i|\theta^r) - y^r_i)^2$. Lastly, we can perform a gradient step on loss $\mathcal{L}(\theta^Q)=\frac{1}{m}\sum_i (Q(s_i, a_i|\theta^Q) - y^Q_i)^2$, with targets: $y^Q_i=r'(s_i, a_i|\theta^{r\prime})+\gamma\max_a Q'(s_{i+1}, a|\theta^{Q\prime}),$ to update the parameters $\theta^Q$ of $Q(\cdot, \cdot|\theta^Q)$. We update target networks by Polyak averaging, i.e. $\theta^{\text{Sh}\prime} \leftarrow (1-\tau) \theta^{\text{Sh}\prime} + \tau \theta^\text{Sh}$, $\theta^{r\prime} \leftarrow (1-\tau) \theta^{r\prime} + \tau \theta^{r}$ and $\theta^{Q\prime} \leftarrow (1-\tau) \theta^{Q\prime} + \tau \theta^{Q}$.Deep Constrained Inverse Q-learning
Following the definition of Constrained Q-learning in Kalweit & Huegle et al., we extend IQL to incorporate a set of constraints $\mathcal{C} = \{ c_i:\mathcal{S} \times \mathcal{A} \rightarrow \mathbb{R} | 1 \le i \le C \}$ shaping the space of safe actions in each state. We define the safe set for constraint $c_i$ as $S_{c_i}(s) = \{a \in \mathcal{A} | \ c_i(s, a) \le \beta_{c_i} \}$, where $\beta_{c_i}$ is a constraint-specific threshold, and $S_\mathcal{C}(s)$ as the intersection of all safe sets. In addition to the Q-function in IQL, we estimate a constrained Q-function $Q^\mathcal{C}$ by: $$Q^\mathcal{C}(s, a) \leftarrow (1-\alpha_{Q^\mathcal{C}}) Q^\mathcal{C}(s, a) + \alpha_{Q^\mathcal{C}} \left(r(s, a) + \gamma \max_{a'\in S_\mathcal{C}(s')} Q^\mathcal{C}(s', a')\right).$$ For policy extraction from $Q^\mathcal{C}$ after Q-learning, only the action-values of the constraint-satisfying actions must be considered. As shown in Kalweit & Huegle et al., this formulation of the Q-function optimizes constraint satisfaction on the long-term and yields the optimal action-values for the induced constrained MDP. Put differently, including constraints directly in IQL leads to optimal constrained imitation from unconstrained demonstrations. Analogously to Deep Inverse Q-learning, we can approximate $Q^\mathcal{C}$ with function approximator $Q^\mathcal{C}(\cdot, \cdot|\theta^\mathcal{C})$ and associated target network $Q^{\mathcal{C}\prime}(\cdot, \cdot|\theta^{\mathcal{C}\prime})$. We call this algorithm Deep Constrained Inverse Q-learning.Results
In Fig. 2 and Fig. 3, we evaluate the performance of IAVI, IQL and DIQL on the common IRL Objectworld benchmark and compare to MaxEnt IRL (closest to IAVI of all entropy-based IRL approaches) and Deep MaxEnt IRL (which is able to recover non-linear reward functions):
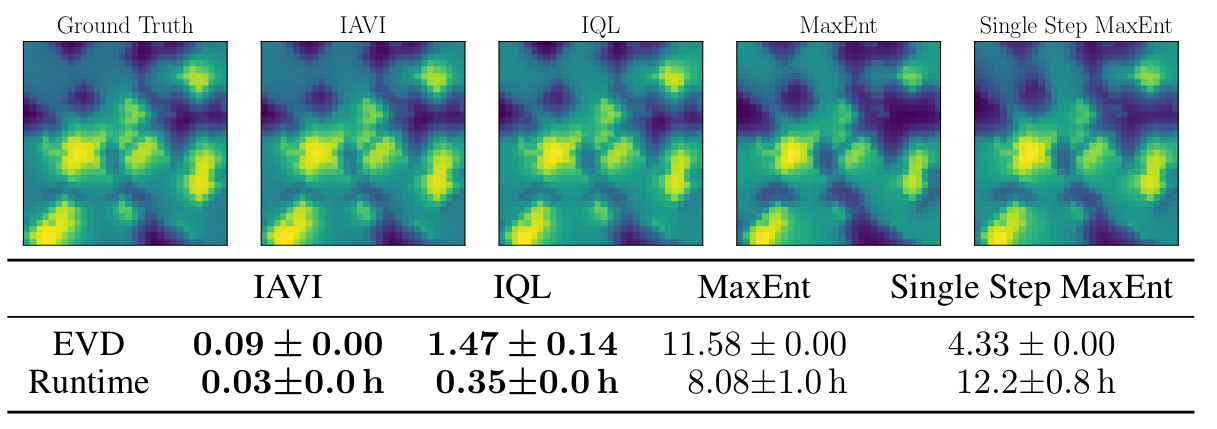
Fig. 2: Results for the Objectworld environment, given a data set with an action
distribution equivalent to the true optimal Boltzmann distribution.
Visualization of the true and learned state-value functions. Resulting expected
value difference and time needed until convergence, mean and standard
deviation over 5 training runs on a 3.00 GHz CPU.
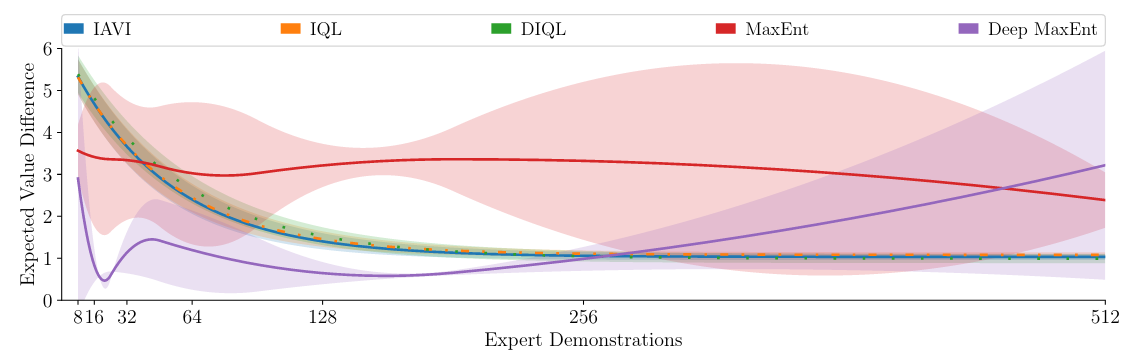
Fig. 3: Mean EVD and SD over 5 runs for different numbers of demonstrations
in Objectworld.
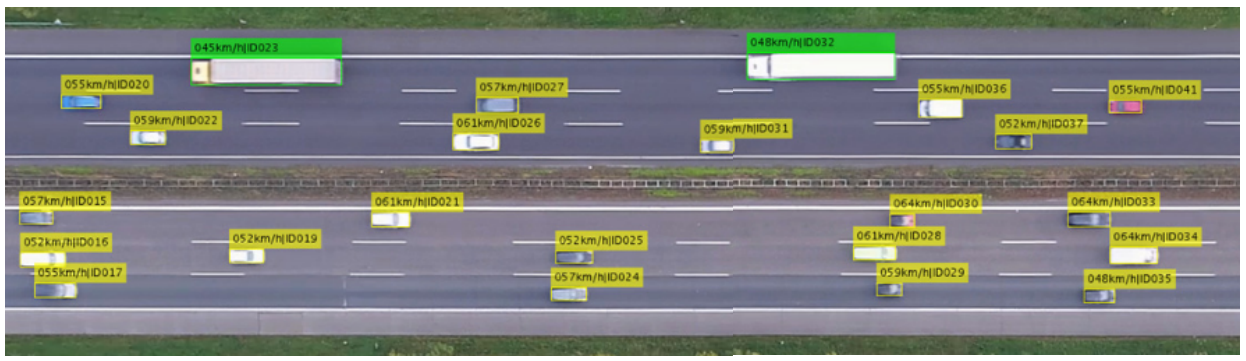
In Fig. 4 we show the potential of constrained imitation by DCIQL on a more complex highway scenario in the open-source traffic simulator SUMO:
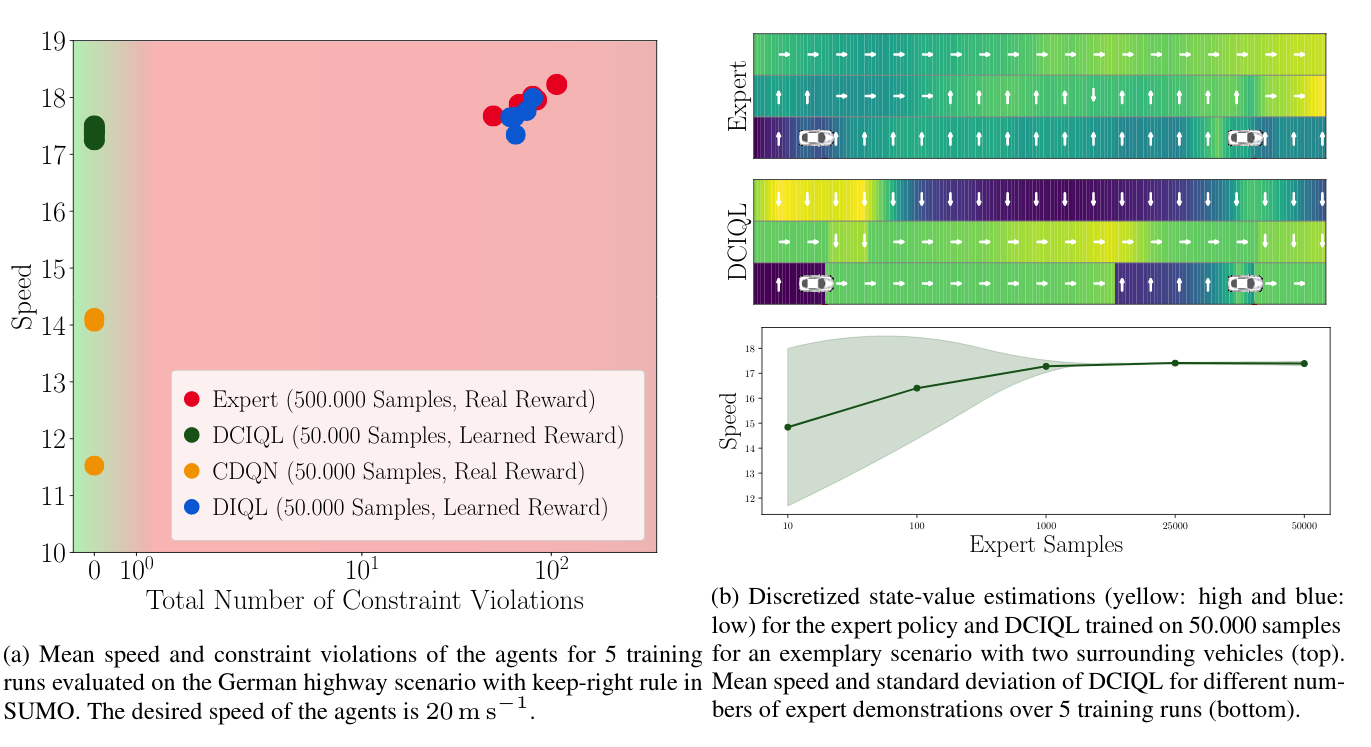
Fig. 4: Results for DCIQL in the autonomous driving task.
Demonstration
Video explaining Deep Inverse Q-learning with Constraints.
BibTeX
@inproceedings{DBLP:conf/nips/KalweitHWB20,
author = {Gabriel Kalweit and
Maria H{\"{u}}gle and
Moritz Werling and
Joschka Boedecker},
title = {Deep Inverse Q-learning with Constraints},
booktitle = {Advances in Neural Information Processing Systems 33: Annual Conference
on Neural Information Processing Systems 2020, NeurIPS 2020, December
6-12, 2020, virtual},
year = {2020},
url = {https://proceedings.neurips.cc/paper/2020/hash/a4c42bfd5f5130ddf96e34a036c75e0a-Abstract.html},
timestamp = {Tue, 19 Jan 2021 15:57:00 +0100},
biburl = {https://dblp.org/rec/conf/nips/KalweitHWB20.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}